检索

许多LLM应用程序需要用户特定数据,这些数据不是模型的训练集的一部分. 完成这一任务的主要方法是通过检索增强生成(RAG). 在此过程中,检索外部数据,然后在生成步骤中将其传递给LLM.
LangChain为RAG应用程序提供了所有的构建模块-从简单到复杂. 本文档部分涵盖了与检索步骤相关的所有内容,例如数据的获取. 虽然听起来很简单,但可能有微妙的复杂性. 这涵盖了几个关键模块.
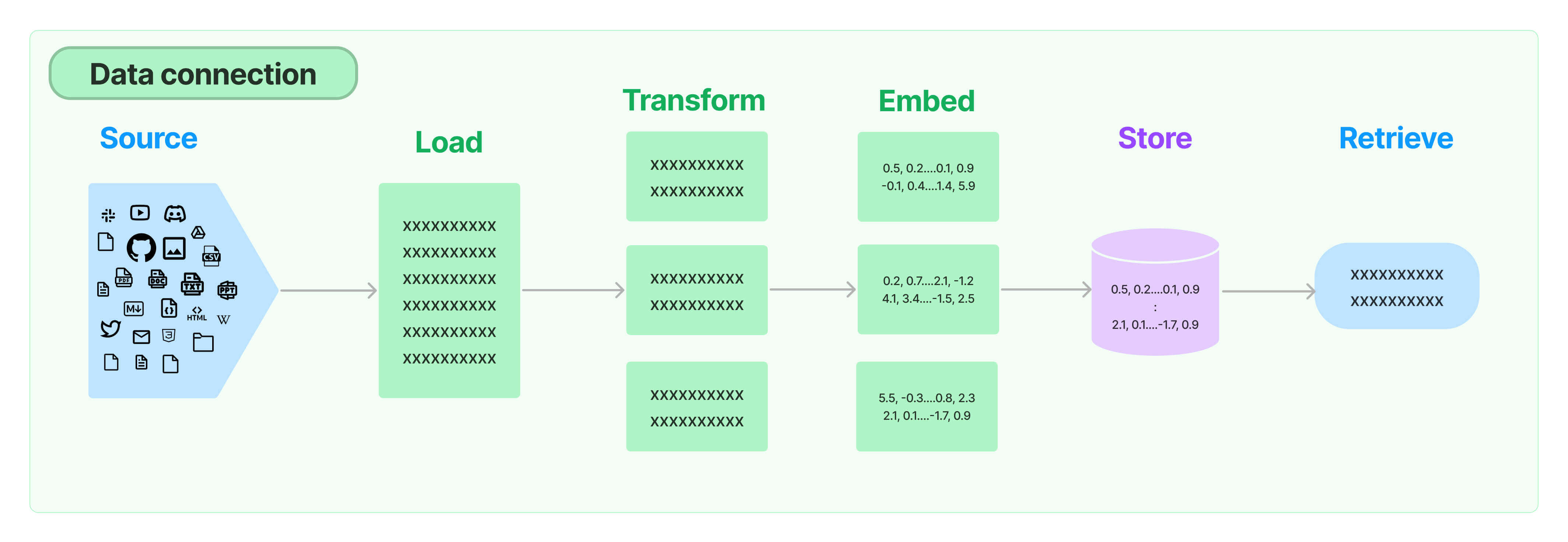
从许多不同来源加载文档. LangChain提供了100多种不同的文档加载器,并与空间中的其他主要提供商(如AirByte和Unstructured)集成. 我们提供了加载各种类型文档(HTML、PDF、代码)的集成,从各种位置(私人S3存储桶、公共网站)加载.
检索的一个关键部分是仅获取文档的相关部分. 为了最好地准备文档以进行检索,这涉及几个转换步骤. 其中一个主要步骤是将大型文档分割(或分块)为较小的块. LangChain提供了几种不同的算法来完成此操作,以及针对特定文档类型(代码、markdown等)进行优化的逻辑.
检索的另一个关键部分是为文档创建嵌入. 嵌入捕捉文本的语义含义,使您能够快速高效地查找其他相似的文本. LangChain与25多个不同的嵌入提供商和方法进行集成, 从开源到专有API, 使您能够选择最适合您需求的一种. LangChain提供了标准接口,使您可以轻松切换模型.
随着嵌入的兴起,出现了对支持这些嵌入的数据库的需求. LangChain与50多个不同的向量存储进行集成,从开源本地存储到云托管专有存储, 使您能够选择最适合您需求的一种. LangChain公开了标准接口,使您可以轻松切换向量存储.
一旦数据在数据库中,您仍然需要检索它. LangChain支持许多不同的检索算法,并且是我们增加最多价值的地方之一. 我们支持易于入门的基本方法-即简单的语义搜索. 但是,我们还添加了一系列算法以提高性能. 这些算法包括: